You maintain a repo. Contributors keep adding methods without doc comments, making your codebase more obscure over time.
You tried to impose a rule: all new methods should be accompanied by a Javadoc (let’s say your software is Java-based). It backfired and turned away some contributors:
- “I wrote the code; why do I have to describe it again?”
- “Writing Javadoc is my 2nd least-favorite thing to do, the first being visiting my in-laws.”
- “Java 已经够难学了,你还要我学英语?(Java is difficult to learn already, and now you want me to learn to write in English?)”
- …
To strike a balance between (1) readability in your repo and (2) relationship with your fellow developers, you wish Javadocs could just magically appear on PRs.
Well, with GPT, you can.
Outline
In this post, I’m going to walk you through the process of creating a bot that suggests Javadocs to methods modified in a PR. The bot will post review comments as a GitHub app, suggesting GPT-generated Javadocs in a “suggested change” box, so that the PR owner can accept the suggestion with one click:
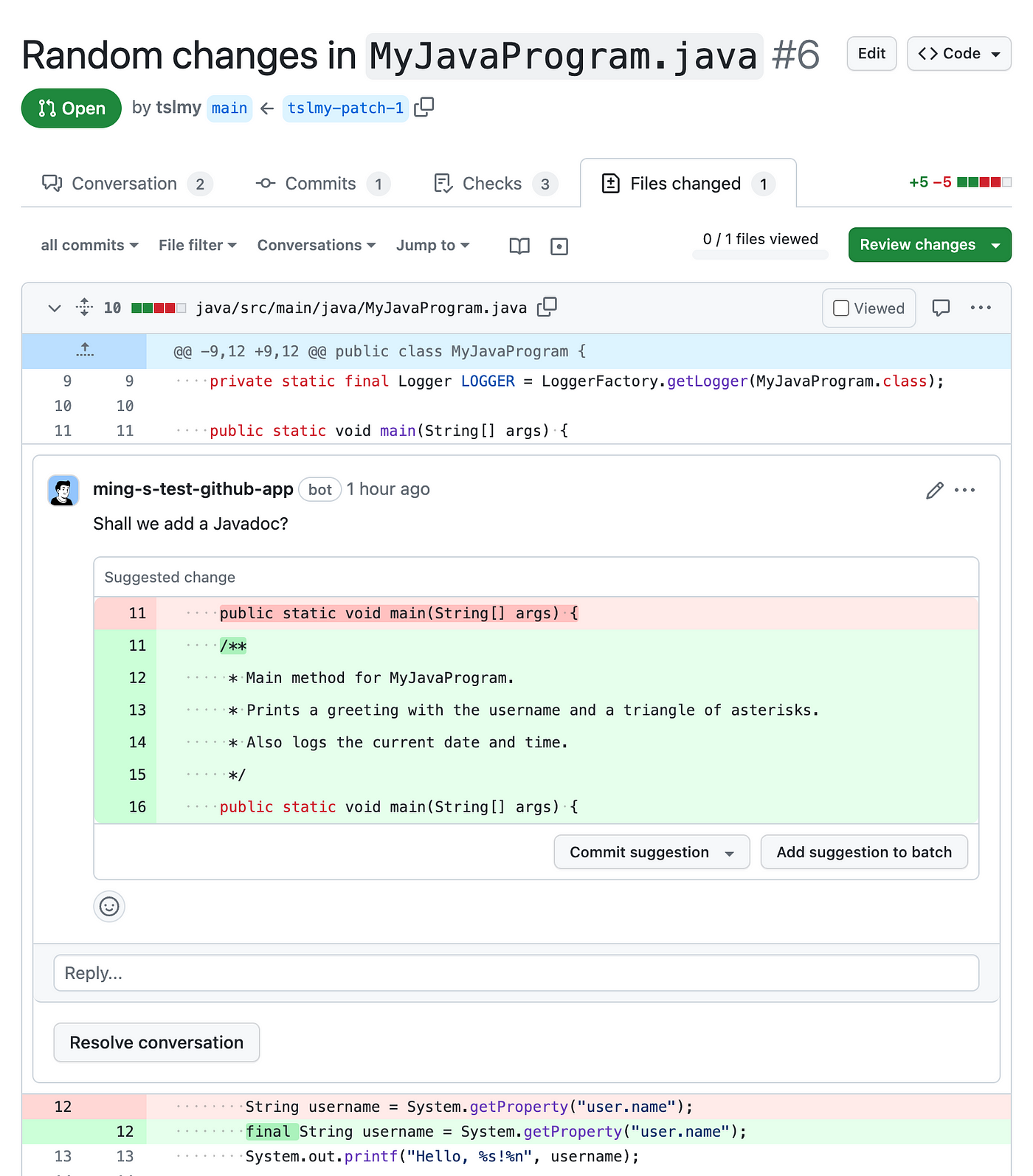
The bot will be a Python script running in a GitHub Workflow. On a high level, it will perform these steps:
- Read the PR as a “unified diff” (via
pygithubandunidiff). - Find Java methods that this PR wants to modify / add, by parsing the syntax tree (via
javalang). - Ask a large language model (LLM) to write a Javadoc for each method (via
langchain). - Publish a review to this PR (again via
pygithub).
Here are some immediate question you might have:
- “I don’t want to send code to OpenAI’s GPT.” No problem. LangChain should allow swapping to other LLMs easily, even locally-served ones.
- “My codebase isn’t in Java.” Not a big deal — Just replace the parser. For example, to parse Go, there’s gopygo.
- “We don’t have workflow runners for our on-premise GitHub Enterprise instance.” Also not an issue. We will write the script as a generic CLI tool, so that you can run it on other CIs like Jenkins.
With the expectations set up, let’s dive into it!
Step 1: Connect to APIs
GitHub forbids reviewing PRs via API as a human user; instead, we have to create a GitHub App and post Javadoc suggestions in the name of it. Fortunately, it only takes ~5 min to complete. Remember to note down:
- The GitHub App ID. This provides authentication.
- The GitHub App Installation ID, which corresponds to the authorization.
- The path to the private key you generated for yout GitHub App.
(In a previous post of mine, I described the registration process and how authn+authz works for GitHub Apps in more details. Please refer to it if you’re interested.)
To use GPT, you’ll also need an API key to OpenAI. I’ll omit the application procedure here.
With all the paperwork done, we can begin our Python script by reading credentials from the environment variable:
if __name__ == "__main__":
github_installation_id = os.environ["GITHUB_INSTALLATION_ID"]
github_app_id = os.environ["GITHUB_APP_ID"]
github_private_key_path = os.environ["GITHUB_PRIVATE_KEY_PATH"]
openai_api = os.environ["OPENAI_API"]… and setting up the connections:
github_private_key = Path(github_private_key_path).expanduser().read_text()
github_integration = GithubIntegration(
integration_id=github_app_id,
private_key=github_private_key,
)
github = github_integration.get_github_for_installation(github_installation_id)
llm = OpenAI(openai_api_key=openai_api)I’ll omit all the import statements. You’re smart enough to figure them out.
Step 2: Download the diff and the modified files
PyGitHub provides Pythonic access to the GitHub API. To retrieve a list of files modified in a particular PR, we just have to do this:
repo = github.get_repo(f'{os.environ["REPO_OWNER"]}/{os.environ["REPO_NAME"]}')
pr = repo.get_pull(int(os.environ["PR_NUMBER"]))
files = pr.get_files()
with tqdm(files, desc="Processing files", total=files.totalCount) as pbar:
for file in pbar:
if not file.filename.endswith(".java"):
continue
# TODOAs an eye candy, I also added progress bar with tqdm . Did you know that “tqdm” is short for “taqaddum”, or “progress” in Arabic? Now you know :D
For each Java file modified, we need its full content before we can parse it:
content_encoded = pr.head.repo.get_contents(
file.filename, ref=pr.head.ref
).content
content_in_utf8 = b64decode(content_encoded)
file_text = content_in_utf8.decode()With the full text in hand, we can use extract all methods declared in it:
tree = javalang.parse.parse(file_text)
methods = []
for _, node in tree.filter(javalang.tree.MethodDeclaration):
start_position, end_position, start_line, end_line = get_method_start_end(
node, tree
)
methods.append(
{
"start_position": start_position,
"end_position": end_position,
"start_line": start_line,
"end_line": end_line,
"node": node,
"is_affected": False,
}
)where get_method_start_end is copied from here. (It’s also a good idea to encapsulate the code block above into its own function, as our script is getting quite long.)
Exercise. In the code block above, I have declared a list methods to store metadata about each Java method we parsed out. All items in the list are dictionaries with a fixed set of keys, making them excellent candidate to be converted to some safer types, such as named tuples and data classes. Try playing around with one and explore how IDEs can help provide more intelligent suggestions while you are working on them.
Notice that I’ve initialized a field called is_affected , which will mark methods that this PR modifies. We detect whether a method is modified by parsing the “unified diff” representation of the PR:
patch = PatchSet("--- /dev/null\n+++ /dev/null\n" + file.patch)[0]
for hunk_id, hunk in enumerate(patch):
for i, line in enumerate(hunk.target):
if not line.startswith("+"):
continue
line_number = hunk.target_start + i
for method_data in methods:
if (
"start_line" in method_data
and method_data["start_line"] > line_number
):
continue
if "end_line" in method_data and method_data["end_line"] < line_number:
continue
method_data["is_affected"] = True
break(Aside: The /dev/null line is a hack that makes the unidiff library work. I explained it with more details in another post.)
Exercise. This block of code filters for lines added to the file (remember: a line modified is — to the eyes of git — merely one line deleted and another added). If you want, you can also handle deleted lines here. One caveat though: you need to read file content from the base revision of the PR, not the HEAD commit as we have been doing, because the line numbers correspond to the old state of the file. I’ll skip dealing with deleted lines for the sake of brevity.
The path forward is clear: We would like to iterate through methods and somehow compose the review comment if needed. . The skeleton is crafted out below:
for method in methods:
if not method["is_affected"]:
continue
comment = compose_pr_comment(method) # TODO
if comment:
comment["path"] = file.filename
pr.create_review(comments=[comment], event="COMMENT")Exercise. Notice how the create_review method is expecting a list of comments, rather than a single one? To improve efficiency, let’s collect all the review comments and publish them in one go, so that we would only make one POST call to GitHub.
Next up, we implement the compose_pr_comment function.
Step 3: Ask LLM to write Javadocs
Now comes the cool part. For each modified method without a Javadoc, we want to prompt a LLM this:
# At the top of your script...
PROMPT_TEMPLATE = """
For the following Java method:
```java
{code}
```
An appropriate Javadoc would be:
"""If most of your experience with LLMs are with ChatGPT, you’ll be tempted to phrase the prompt like a question, such as:
“For the following Java method […] What would be an appropriate Javadoc?”
That, however, isn’t optimal when interacting with a lower-level, not-fine-tuned, base LLM like GPT-3.5. With the latter, you should phrase your words as if you stopped mid-sentence and is expecting LLM to “auto-complete” your lines, hence the term “prompt”.
With the template string declared, we can initialize the LLM connection now:
# At the top of your script...
PROMPT = PromptTemplate(template=PROMPT_TEMPLATE, input_variables=["code"])
# Later under `if __name__ == "__main__"`...
llm = OpenAI(openai_api_key=openai_api)
llm_chain = LLMChain(prompt=PROMPT, llm=llm)This llm_chain object can be triggered like this:
def generate_pr_comment_for_adding_javadoc(
method_data: dict
):
# TODO
llm_response = llm_chain.run(method_text)
# TODOwhere method_text can be extracted from the file_text using the metadata we’ve collected. Again, we can use the code snippet shared here.
def generate_pr_comment_for_adding_javadoc(
method_data: dict
):
method_text = get_method_text(
method_data["start_position"],
method_data["end_position"],
method_data["start_line"],
method_data["end_line"],
last_endline_index=None,
codelines=file_text.split(os.linesep),
)
llm_response = llm_chain.run(method_text)
# TODONow, we have the LLM’s response to play with.
Step 4: Compose the suggestion
We know that LLMs can be flaky at times — We can’t be sure LLM will always give us a string of valid Java comment and nothing else. Therefore, it’s wise to search through its response with a regular expression:
match = JAVADOC_PATTERN.search(llm_response)
if not match:
return None
javadoc = match.group(0).strip()where JAVADOC_PATTERN shall be declared (at the top of our script) as:
JAVADOC_PATTERN = re.compile(r"/\*\*.+?\*/", re.DOTALL)Aside. From the perspective of information security, ensuring that all the code suggestions you’re getting from a third-party is wrapped as a comment is also a good idea. If you’re doing following this tutorial at your workplace, your InfoSec team will thank you.
Similarly, you shouldn’t expect LLM to have indented lines properly for you. It’s best to just re-indent the Javadoc string ourselves:
first_line_of_code = method_text.split(os.linesep)[0]
# Find how much `first_line_of_code` is indented.
first_line_of_code_indent = len(first_line_of_code) - len(
first_line_of_code.lstrip()
)
# Indent every line in `javadoc` variable as how `first_line_of_code` is indented.
indent = " " * first_line_of_code_indent
javadoc = indent + javadoc.replace("\n", "\n" + indent)The variable first_line_of_code will be reused in composing the suggestion. On GitHub, every comment must be anchored at a line of code, so we want to write our suggestion of “adding before the first line” as a suggestion of “replacing the first line with something else plus itself”.
Speaking of GitHub, this is also where we can wrap up our journey by composing the ReviewComment object, per GitHub API:
def generate_pr_comment_for_adding_javadoc(
method_data: dict
) -> Optional[dict]:
...
return {
"body": COMMENT_TEMPLATE.format(
javadoc=javadoc,
first_line_of_code=first_line_of_code,
).strip(),
"line": method_data["start_line"],
"start_side": "RIGHT",
}where COMMENT_TEMPLATE is another template string constant that should be put at the top of the script:
COMMENT_TEMPLATE = """
Shall we add a Javadoc?
```suggestion
{javadoc}
{first_line_of_code}
```
"""Recall that this returned dictionary will be fed into the pr.create_review method, which will assume the identity of your GitHub App (from Step 1 — sounds like a long time ago?). Our trip is complete.
The final missing piece is to create a GitHub workflow that gets triggered every time a PR is opened / pushed to. Since I’m no expert on that matter (my workplace uses Jenkins, as you might be able to tell from my recent posts), I asked ChatGPT to generate one for us:
name: AutoJavadoc Workflow
on:
pull_request:
types:
- opened
- synchronize
jobs:
autojavadoc:
runs-on: ubuntu-latest
env:
GITHUB_INSTALLATION_ID: ${{ secrets.GITHUB_INSTALLATION_ID }}
GITHUB_APP_ID: ${{ secrets.GITHUB_APP_ID }}
GITHUB_PRIVATE_KEY_PATH: ${{ secrets.GITHUB_PRIVATE_KEY_PATH }}
OPENAI_API: ${{ secrets.OPENAI_API }}
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.11
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install langchain docopt pygithub tqdm unidiff openai javalang
- name: Run autojavadoc.py
run: python autojavadoc.py
env:
GITHUB_INSTALLATION_ID: ${{ env.GITHUB_INSTALLATION_ID }}
GITHUB_APP_ID: ${{ env.GITHUB_APP_ID }}
GITHUB_PRIVATE_KEY_PATH: ${{ env.GITHUB_PRIVATE_KEY_PATH }}
OPENAI_API: ${{ env.OPENAI_API }}Summary
In this article, I walked through the construction of a Python script that suggests Javadocs to a PR where they are missing. The end result is that PR authors who felt a strong distaste to writing doc comments can be less deterred from contributing to your codebase. On the other hand, you, as the repo maintainer, don’t have to lower the standards of documenting code in your repo. It’s a win-win.
Personally, I feel that this is the one excellent use of language models, using what it’s best at — generating natural language texts. A similar idea is to automate the writing of PR descriptions when the PR author didn’t bother to, which I actually have implemented at my workplace.
Are these ideas beneficial to software engineering in general, or are they spoiling developers by shielding them from opportunities to practice their writing skills? What do you think?
